Million event Erlang “like” engine

Inspiration:
Facebook has a very unique and custom architecture to handle millions of likes on its posts every second. Sometimes a post is so catchy that it will attract millions of likes per second and being a fan of that article you don’t want to miss its live statistics.
Shorten the goal:
My goal is to create a like engine with can handle millions of likes per second. Let it be 1 like for 1 article/URL or 1000 likes for 1000 articles/URLs or 1 article/URL with million likes.
The architecture:
I have taken a very naive approach to solve this problem. I have created a event_manager with gen_event behavior to handle the events related to likes.
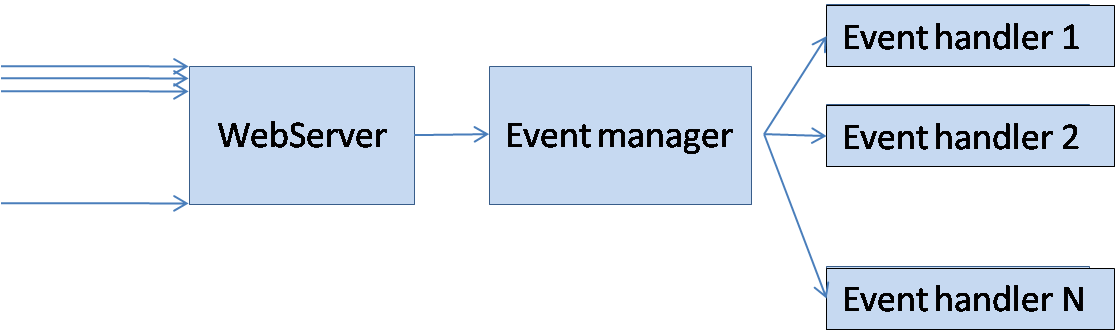
Why gen_event? I assume that I have webserver which listens for the events/requests from the client applications. This webserver is basically used to catch all the events without missing even one. The webserver will call an event to the event_manager process. Event handlers can be added to the event_manager process to handle events related to likes,unlikes,impressions etc. I mean, an event handler for like and unlikes, one for impressions and so on.
Whenever an event_manager is started, following are performed: 1. Creates an ets table with ordered_set option and the control to edit it is given to the event_manager. 2. Adds an event handler to handle particular events. 3. Starts a batcher process which takes care of batching at regular intervals 4. Starts a worker_pool_man process which acts as an interface for worker_pool_sup process which is gen_supervisor behavior.
Worker pool manager:
This is a gen_server process.
This basically starts the worker pool supervisor with a default number of workers(100+10(10% extra buffer processes)) and stores the list of these worker process ids in the state variable.
It contains functions to get a new worker process and also to kill some worker process when it is hung up/unresponsive.
Worker pool supervisor:
This is a gen_supervisor behavior process with simple_one_for_one. Good thing about it is you can start just the supervisor process without any workers or child processes initially and you can add them or remove them on fly.
Worker process:
It is a gen_server process which holds a state of the article/URL. The state contains a counter of the current like count. Since the counter is maintained in memory, many thousands of increments or decrements can be performed concurrently.
Each worker process is initially registered, which means the counter value will be set to 0. a commit request to the worker process will retrieve the current counter value.
Batcher process:
This is a gen_server process constantly listens to the event_manager to check whether the ETS table has reached its predefined limit. Whenever ETS table linked to the eventmanager process reaches 2000 unique URL count, it signals the batcher process to take control of it. Batcher reads all the ETS entries and writes them to a file(tab
How the whole thing works?
Events coming into the web server are delivered to the event manager which in turn handled by the corresponding event handler. Every event is scrutinised and URL is extracted and stored in the ETS table if it doesn’t already exists. Here ETS table is created with ordered_set strategy but not a bag to store only unique entries. For every new entry into the ETS table a worker process is allocated by calling a worker pool manager. Worker pool manager allocates a worker process from its own list of buffer workers. However these worker processes are obtained from worker pool supervisor process. This is all about a new URL like event coming in.
What If we got a like from the same URL? Now it checks for its existence in the ETS table and get its worker process PID. As each and every worker process is a gen_server process. We basically give a cast call to it update the in memory counter for that particular URL.
That’s it, let us say, we have 1000 unique URL’s with 1000 likes coming in. You will have 1000 processes with counter value of 1000 for each one of them.
Or, we say, 1 million “like” events for a single URL also works by creating a single worker process with counter value of 1000000.
What happens next??
When the ETS table entry size reaches a certain predefined size. The table is given away to the BATCHER process which starts iterating over all the table entries and collects the like count and writes it to a file and then throws the table away. In this meantime, the event is not alone without the ETS table, it will create a new table and starts filling it up for the batcher process to be taken care of. While the batching is being done, the event manager is never blocked instead writes into a new table and new worker processes.
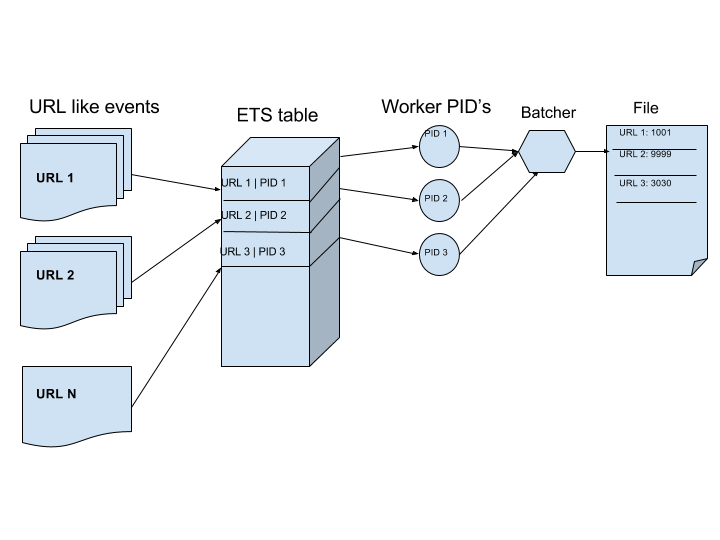
Events -> ETS table -> worker processes -> batcher -> file
After batching an ETS table, the worker process ID’s are again donated to the event pool manager to be reused. If some process is too much used and hanging around for a while and sluggish, we simply kill it and spin up a new one to replace it. This is how we keep up the supply of worker processes for the demand.
Going Live(Not yet implemented):
Another process can be employed to read these files in a sequential order of their creation time. Let us say we read 1000 URL’s and will be updating the database whose write tolerance may be limited. This process would have the privilege to control the read based on the write tolerance of the database to which these statistics have to be updated.
Credits:
Thanks to Konstantin Tcepliaev at 24[7] campanja, who has given me this challenge.